RCU 是 2002 年添加到 Linux 内核的一种同步机制。RCU 允许多个 reader 和单个 writer 并发使用。
RCU 通过维护多个版本的值来保证 reader 的一致性,同时定义了一个高效和可伸缩的机制来发布新对象和延长析构旧对象。这些机制允许读和写以一种非常快的形式进行。在某些情况下(非抢占式内核)中 RCU 读端是没有任何开销的。
RCU 由三个基础机制构成:
发布订阅机制(用于插入)
等待先前的 reader 完成(用于删除)
维护最近更新对象的多个版本(允许 reader 容忍并发插入和删除)
发布订阅机制
RCU 一个关键属性是允许在修改过程时安全地读取值。RCU 使用所谓的发布订阅的机制来实现这个功能。比如,假设有一个被初始化为 NULL 的全局指针变量 gp 需要被更新,下面的代码可用于此目的:
struct foo {
int a;
int b;
int c;
};
struct foo *gp = NULL;
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
gp = p;不幸的是并没有办法阻止编译器和 CPU 按序运行最后四行代码。如果 gp = p 在初始化字段之前运行,reader 就会看到未初始化的值。要保证执行顺序就需要使用内存屏障,但是内存屏障是出了名的难用。因此我们将它封装成一个具有发布语义的原语 rcu_assign_pointer()。下面的四行因此可以修改成:
p->a = 1;
p->b = 2;
p->c = 3;
rcu_assign_pointer(gp, p);rcu_assign_pointer() 用来发布新的解国体,强制编译器和 CPU 在初始化字段之后才分配。
然而只在 updater 上执行排序是不够的,考虑下面的读端代码:
p = gp;
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}看起来似乎没有问题,但是 DEC Alpha CPU 和值优化(value-speculation)的编译器可能会在读取 p 的值之前先读取 p→a, p→b, p→c 的值。这种优化相当激进,但是确实会发生在 profile 驱动的优化中。
显然,我们需要阻止编译器和 CPU 的这种行为。rcu_dereference() 原语被用于此目的:
rcu_read_lock();
p = rcu_dereference(gp);
if (p != NULL) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();rcu_dereference() 被视为给定指针的值,保证后续的解引用操作会在发布(rcu_assign_pointer())之后。rcu_read_lock() 和 rcu_read_unlock() 的调用也是需要的,它们共同构成了 RCU 的读临界区,它们的用途在下一节降到。然而它们实际上并没有任何自旋或者阻塞行为,也不会阻止 list_add_rcu() 操作。实际上在非抢占式内核中,它们不会生成任何代码。
尽管 rcu_assign_pointer() 和 rcu_dereference() 理论上能够被用于任何被 RCU 保护的数据结构,但是实际上他们被构造成更高级的结构。rcu_assign_pointer() 和 rcu_dereference() 原语被嵌入到 Linux RCU-list 的相关 API 中。Linux 有两种变体的双向链表:环形的 list_head 和现行的 hlist_head/hlist_nodde。前者的布局如下:

将指针发布示例改编为链表示例,可得到如下结果:
struct foo {
struct list_head list;
int a;
int b;
int c;
};
LIST_HEAD(head);
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
list_add_rcu(&p->list, &head);第十五行阻止了多个 list_add() 实例并发执行。然而这种机制并没有办法阻止 list_add() 和 RCU readers 并发执行。
订阅一个 RCU 保护的 list 也很简单:
rcu_read_lock();
list_for_each_entry_rcu(p, head, list) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();list_add_rcu() 原语将 entry 发布到指定的 list 中,然后 list_for_each_entry_rcu() 保证订阅能够正确读取 entry。
Linux 的另一个双链表 hlist 是一个线性表,这意味着它只需要一个指针作为表头,而不是循环列表所需的两个指针。

发布一个新 entry 到 RCU 保护的 hlist 和循环链表类似:
struct foo {
struct hlist_node *list;
int a;
int b;
int c;
};
HLIST_HEAD(head);
/* . . . */
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
hlist_add_head_rcu(&p->list, &head);和先前类似,第 15 行通过同步机制保护了内存顺序。
订阅一个 RCU 保护的 hlist 也和循环链表类似:
rcu_read_lock();
hlist_for_each_entry_rcu(p, q, head, list) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();RCU 发布、订阅和撤销原语在下表列出:
| 类型 | 发布 | 撤销 | 订阅 |
|---|---|---|---|
指针 | rcu_assign_pointer() | rcu_assign_pointer(…, NULL) | rcu_dereference() |
Lists |
| list_del_rcu() | list_for_each_entry_rcu() |
Hlists |
| hlist_del_rcu() | hlist_for_each_entry_rcu() |
等待先前的 reader 完成
就最基本形式而言,RCU 只是用来等待某些东西结束。当然还有很多其它的东西可以用来等待,比如引用计数、读写锁、事件等等。RCU 最大的优点就是它可以跟踪 20,000 不同的东西而无须显示跟踪,而且还不需要担心性能损坏、可伸缩性限制、复杂的死锁、内存泄露等等。
RCU 中用来等待的东西被称作 RCU 读端临界区。RCU 读端临界区从一个 rcu_read_lock() 原语开始,到 rcu_read_unlock 原语结束。读端临界区允许嵌套并包含任意多无显式阻塞和睡眠的代码(尽管一种 RCU 的变体 SRCU 允许进行一般性等待)。
RCU 通过间接确定这些其他工作何时完成来实现这一功能,这一点在其他地方的 RCU Classic 和 实时 RCU 中已有描述。
具体而言,如下图所示,RCU 是一种等待预先存在的 RCU 读端临界区完全结束的方法,包括这些临界区执行的内存操作:
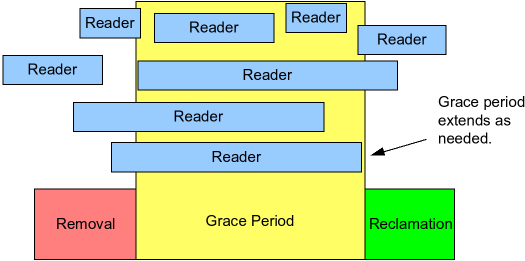
下面的伪代码描述了使用 RCU 等待 readers 算法的基本形式:
进行更改,例如替换链表中的一个元素。
等待所有已经存在的 RCU 读端临界区结束(例如使用
synchronize_rcu()原语)。这里的关键是,后续的 RCU 读端临界区无法获得对新删除元素的引用。清理。例如释放上述被替换的元素。
以下代码片段改编自 上一节的代码,演示了这一过程,其中字段 a 是搜索关键字:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
struct foo {
struct list_head list;
int a;
int b;
int c;
};
LIST_HEAD(head);
/* . . . */
p = search(head, key);
if (p == NULL) {
/* Take appropriate action, unlock, and return. */
}
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);
第 19, 20, 21 行实现了上面提到的第三个步骤,16-19 行实现了所谓的 RCU(read-copy update):在允许并发读的情况下, 16 行拷贝,17-19 行更新。
synchronize_rcu() 看起来优点神秘,毕竟它必须等待所有的 RCU 读端临界区结束,但是正如我们先前提到的,rcu_read_lock() 和 rcu_read_unlock() 在非抢占式内核中并没有生成任何代码。
因此,RCU 传统的 synchronize_rcu() 概念上类似于下面的代码:
for_each_online_cpu(cpu)
run_on(cpu);这里 run_on() 将当前线程切换到指定 CPU,这强制目标 CPU 发生依次上下文切换。for_each_online_cpu() 循环因此会导致所有的 CPU 发生上下文切换,从而保证所有先前 RCU 读端临界区都已经完成。这种简单的形式适用于非抢占式内核。因此对于抢占式实时内核,http://lwn.net/Articles/253651/[实时 RCU] 形式上参考了引用计数。
当然,Linux 中的实际实现更加复杂,它需要考虑终端、NMIs、CPU 热插拔等。
尽管知道有一个简单的 synchronize_rcu()概念实现是件好事,但其他问题依然存在。例如,当并发遍历更新的列表时,RCU readers 到底能看到什么?下一节将讨论这个问题。
维护最近更新对象的多个版本
在删除过程中维护多个版本
我们修改 上一节 代码中的 11 - 21 行实现删除功能:
1
2
3
4
5
6
p = search(head, key);
if (p != NULL) {
list_del_rcu(&p->list);
synchronize_rcu();
kfree(p);
}
列表的初始状态如图:

每个元素都有包含了一个三元组 a, b, c。红色的 border 表示可能有 readers 持有指向它的引用。reders 可能和 writer 并发执行。
在第三行的 list_del_rcu() 挖成后,元素 5, 6, 7 从列表中被移除,如下图所示。由于 readers 没有直接和 updaters 同步,此时 reade 可能还在扫描 lists。这些并行的 readers 可能并不会看到元素被删除。

请注意,在 reader 退出读端临界区后它们不得持有对元素的引用。因此一旦第四行的 synchronize_rcu() 完成,就能保证没有 reader 持有对 reader 的引用。就像下面黑色边框指示的那样,我们 list 现在只有一个版本:

在这里,元素 5, 6, 7 可以被安全释放,最后形态如下:

在这里,我们完成了对元素 5, 6, 7 的删除。
在替换时维护多个版本
我们修改 上一节 的代码中现删除功能:
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);列表的初始状态如下:
第一行的 kmalloc() 替换一个元素,如下图所示:

第二行将旧元素拷贝到新元素:

第 3, 4 行更新了 q→b 和 q→c

第五行进行了替换:

在 synchronize_rcu() 返回后,宽限期将结束,因此所有的读端临界区都会退出,这时没有 reader 再持有对 5,6,7 元素的引用,因此可以安全删除:

在 kfree() 执行结束后,list 将会变成下面的样子:

总结
从上面可以看出,RCU 和 COW 的不同之处在于:
RCU 读端是无开销的,而 COW 需要执行一次 fetch_add/fetch_sub。
RCU 存在宽限期,而 COW 通过引用计数来释放内存,无宽限期的存在。
尽管原子操作不像传统的同步机制那样会导致大量的流水线被清空,当时当多核同时读取一个状态时会导致缓存一致性协议的介入,从而确保不同 CPU 上的缓存是一致的。换句话说,原子操作导致其它核上的缓存失效。在高并发环境下频繁的缓存失效会导致巨大的性能开销。 |
抢占式 RCU
由于此实现不需要内存屏障(rcu_read_lock/rcu_read_unlock)因此需要一个多阶段宽限期探测算法。
在两阶段宽限期实现中,任意两个连续的阶段都是一个完全的宽限期。
要跟踪一个宽限期 stage 结束,抢占式 RCU 使用了一个包含了两个元素的 per-CPU 数字 rcu_flipctr 来跟踪 RCU 读端临界区。rcu_flipctr 中的一个元素用来跟踪上一个 stage 的读端临界区,另一个元素用来跟踪当前 stage 的读端临界区。每当进入新的宽宽限期 stage 开始时,都会交换数组的两个元素。
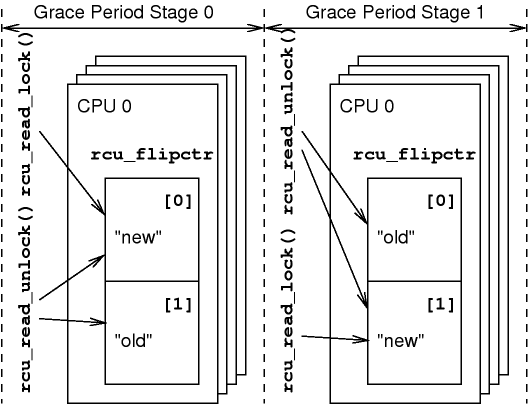
在左侧的第一个 stage 中,rcu_flipctr[0] 跟踪新的 RCU 读端临界区。rcu_read_lock() 会递增 rcu_flipctr[0],rcu_read_unlock() 会递减 rcu_flipctr[0]。类似的,rcu_flipctr[1] 跟踪旧的读端临界区。并且只会减小不会增加。
由于每个 CPU 的 rcu_flipctr[1] 元素都不会增加,因此他们所有 CPU 的和最终必定为零。单个计数器不为零甚至变成负数。例如,假设有一个任务调用了 rcu_read_lock() 然后发生抢占后被调度到另一个 CPU 上调用了 rcu_read_unlock()。但是它们的和总是零。不管是否抢占,当旧计数器的总和为零时,就可以安全地移动到宽限期的下一个 stage。这体现在上图中的右侧。
在第二个 stage 中,CPU 的 rcu_flipctr 计数器切换了含义,rcu_flipctr[0] 计数器现在跟踪旧 RCU 读端临界区,也就是宽限期的 stage0,rcu_flipctr[1] 跟踪新的读端临界区,也就是宽限期 stage 1.因此 rcu_read_lock() 现在在宽限期 stage0 上运行(旧的 stage 上),rcu_read_unlock 也在相同阶段上运行,但是如果 rcu_read_lock 运行在 satge1,则 rcu_read_unlock 也必须运行在 rcu_flipctr[1] 上。
关键点在于所有跟踪旧 RCU 读端临界区的 rcu_flipctr 必须严格递减,一旦计数器的和为零,它就不能更改了。
rcu_read_lock() 原语通过读取当前宽限期计数器的底部位(rcu_ctrlblk.completed & 0x1)来索引 rcu_flipctr 数组,并将这个索引记录到 task 结构体中。与其匹配的 rcu_read_unlock() 使用这个索引确保递减的计数器是 rcu_read_lock() 递增的那个计数器。当然,若一个 RCU 读端临界区中发生了抢占,rcu_read_lock() 可能会在另一个 CPU 上递减计数器。
每个 CPU 还索引了 rcu_flip_flag 和 rcu_mb_flag 两个 per-CPU 变量。rcu_flip_flag 变量用来匹配每个宽限期 stage 的开始:一旦给定 CPU 响应了它的 rcu_flip_flag,它就不能再增加 rcu_flip 数组元素了,因为这个元素已经代表了旧的 stage。The CPU that advances the counter (rcu_ctrlblk.completed) changes the value of each CPU’s rcu_mb_flag to rcu_flipped, but a given rcu_mb_flag may be changed back to rcu_flip_seen only by the corresponding CPU. The rcu_mb_flag variable is used to force each CPU to execute a memory barrier at the end of each grace-period stage. These memory barriers are required to ensure that memory accesses from RCU read-side critical sections ending in a given grace-period stage are ordered before the end of that stage. This approach gains the benefits of memory barriers at the beginning and end of each RCU read-side critical section without having to actually execute all those costly barriers. The rcu_mb_flag is set to rcu_mb_needed by the CPU that detects that the sum of the old counters is zero, but a given rcu_mb_flag is changed back to rcu_mb_done only by the corresponding CPU, and even then only after executing a memory barrier.
数据结构
这部分描述了 RCU 的主要数据结构,包括 rcu_ctrlblk, rcu_data, rcu_flipctr, rcu_try_flip_state, rcu_try_flip_flag 和 rcu_mb_flag。
rcu_ctrlblk rcu_ctrlblk 是一个全局变量。维护了宽限期锁(fliplock)和宽限期计数器(completed)。completed 的最低有效位被 rcu_read_lock 用来确定递增哪个计数器。
rcu_data rcu_data 结构是一个 per-CPU 结构。包含了以下字段:
| 字段 | 用途 |
|---|---|
lock | 保护这个结构体的其它字段 |
completed | 和 rcu_rcu_ctrlblk 一起保护本地 CPU 活动 |
waitlistcount | 用来维护一个非空等待列表的计数器。这个字段被 rcu_pending() 用来确定当前 CPU RCU 相关的工作是否结束。 |
nextlist, nextail, waitlist, waitail, donelist | 包含了等待宽限期结束的毁掉列表。每个列表都有一个 tail 指针,允许 O(1) 时间的 append。RCU 回调这些列表的方式如下图。 |
rcupreempt_trace | 用来统计 |
rcu_flipctr 正如先前提到的,rcu_flipctr per-CPU 数组维护了读端临界区 stage 的计数器。
rcu_try_flip_state rcu_try_flip_state 变量跟踪了当前 宽限期状态机。
rcu_try_flip_flag
rcu_mb_flag

宽限期状态机

下图显示了状态机是如何随着时间的推移而运行的。状态沿图的左侧显示,相关事件沿时间轴显示,时间沿下行方向进行。我们将在稍后章节验证算法时详细说明该图。
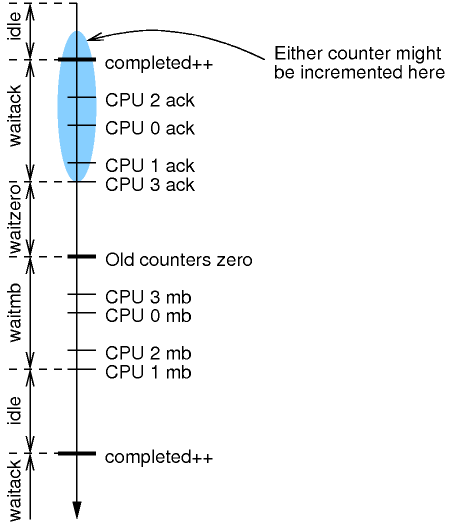
这里对上图进行更进一步的解释:
rcu_ctrlblk.completed 计数器的递增会在不同的时间被不同的 CPU 看到,就像蓝色椭圆那样。然而,一旦给定 CPU 完成了确认,它就只能使用新计数器。这样一旦所有的 CPU 完成了确认,旧的计数器就能够进行递减。
CPU 只会在对计数器递增确认之间添加回调列表。
蓝色椭圆代表了一个事实:由于指令重排的原因,不同的 CPU 可能会在不同的时间看到计数器的递增。这意味着给定 CPU 可以认为其它 CPU 可能比自己更显看到递增,并在计数器实际递增之前使用新的计数器。理论上,给定 CPU 最早可能和上一个内存屏障指令一起看到了递增。
由于 rcu_read_lock() 并不包含任何的内存屏障指令,因此对应的 RCU 读端临界区指令重排可能会导致其位于 rcu_read_unlock 之后。因此这里必须使用内存屏障以确保读端临界区已经完成。
正如我们将要看到的,不同的 CPU 可以在不同的时间看到计数器翻转,这就意味着单次通过状态机并不能满足宽限期的要求:需要多次通过状态机。
宽限期状态机演示
这节演示了 C 语言实现的 RCU 宽限期状态机,这些代码是在 scheduling-clock 中断调用的。其在禁用了 irqs(因此也禁用了抢占 的条件下调用了 rcu_check_callbacks(),函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
void rcu_check_callbacks(int cpu, int user)
{
unsigned long flags;
struct rcu_data *rdp = RCU_DATA_CPU(cpu);
rcu_check_mb(cpu);
if (rcu_ctrlblk.completed == rdp->completed)
rcu_try_flip();
spin_lock_irqsave(&rdp->lock, flags);
RCU_TRACE_RDP(rcupreempt_trace_check_callbacks, rdp);
__rcu_advance_callbacks(rdp);
spin_unlock_irqrestore(&rdp->lock, flags);
}
第 4 行选中了当前 CPU 对应的 rcu_data 结构体,然后在第 6 行检查了是否需要运行内存屏障来推进 rcu_try_flip_waitmb_state 状态机。第 7 行检查是否 CPU 已经知道了当前宽限期 stage 编号,如果是这样,则第 8 行尝试推进状态机。第 9 - 12 行对 rcu_data 进行了加锁,第 11 行则在合适的情况下推进回调函数。如果启用了 CONFIG_RCU_TRACE,则第 10 行会统计 RCU 信息。
rcu_check_mb 函数会按需执行内存屏障:
1
2
3
4
5
6
7
static void rcu_check_mb(int cpu)
{
if (per_cpu(rcu_mb_flag, cpu) == rcu_mb_needed) {
smp_mb();
per_cpu(rcu_mb_flag, cpu) = rcu_mb_done;
}
}
第 3 行检查当前 CPU 是否需要运行内存屏障,如果需要,第 4 行进行执行,并在第 5 行通知状态机。注意这个内存屏障确保了任何看到了 rcu_mb_flag 新值的 CPU 也会看到内存屏障被当前 CPU 执行了。
rcu_try_flip() 函数实现了 RCU 宽限期临界区的顶级函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static void rcu_try_flip(void)
{
unsigned long flags;
RCU_TRACE_ME(rcupreempt_trace_try_flip_1); (1)
if (unlikely(!spin_trylock_irqsave(&rcu_ctrlblk.fliplock, flags))) { (2)
RCU_TRACE_ME(rcupreempt_trace_try_flip_e1);
return;
}
switch (rcu_try_flip_state) {
case rcu_try_flip_idle_state:
if (rcu_try_flip_idle())
rcu_try_flip_state = rcu_try_flip_waitack_state;
break;
case rcu_try_flip_waitack_state:
if (rcu_try_flip_waitack())
rcu_try_flip_state = rcu_try_flip_waitzero_state;
break;
case rcu_try_flip_waitzero_state:
if (rcu_try_flip_waitzero())
rcu_try_flip_state = rcu_try_flip_waitmb_state;
break;
case rcu_try_flip_waitmb_state:
if (rcu_try_flip_waitmb())
rcu_try_flip_state = rcu_try_flip_idle_state;
}
spin_unlock_irqrestore(&rcu_ctrlblk.fliplock, flags); (3)
}
| 1 | 收集 RCU 统计信息。 |
| 2 | RCU 状态机加锁,如果失败则返回。 |
| 3 | RCU 状态机解锁。 |
高亮部分执行了状态机。对于每个执行的函数,如果状态需要推进返回 1,否则返回 0。理论上下一个状态可以被立即执行,但实际上我们不会这样做以减少延迟。
rcu_try_flip_idle() 函数在状态机空闲时调用,因此也需要在需要的时候启动状态机,下面是它的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
static int rcu_try_flip_idle(void)
{
int cpu;
RCU_TRACE_ME(rcupreempt_trace_try_flip_i1);
if (!rcu_pending(smp_processor_id())) { (1)
RCU_TRACE_ME(rcupreempt_trace_try_flip_ie1);
return 0;
}
RCU_TRACE_ME(rcupreempt_trace_try_flip_g1);
rcu_ctrlblk.completed++; (2)
smp_mb(); (3)
for_each_cpu_mask(cpu, rcu_cpu_online_map) (4)
per_cpu(rcu_flip_flag, cpu) = rcu_flipped;
return 1; (5)
}
| 1 | 检查当前 CPU 是否有任何 RCU 相关的工作。 |
| 2 | 递增宽限期 stage 计数器。 |
| 3 | 确保 CPU 在看到确认请求之前先看到新的计数器值。 |
| 4 | 设置所有 CPU 的 rcu_flip_flag。 |
| 5 | 告诉上级推进状态机。 |
rcu_try_flip_waitack() 函数检查是否所有的在线 CPU 已经确认了计数器翻转(实际上就是自增,但是由于 rcu_read_lock() 使用最低为所以 rcu_flipctr 数组,因此叫作翻转)。如果是,则告诉顶级状态机移动到下一个状态:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
static int rcu_try_flip_waitack(void)
{
int cpu;
RCU_TRACE_ME(rcupreempt_trace_try_flip_a1);
for_each_cpu_mask(cpu, rcu_cpu_online_map) (1)
if (per_cpu(rcu_flip_flag, cpu) != rcu_flip_seen) { (2)
RCU_TRACE_ME(rcupreempt_trace_try_flip_ae1);
return 0;
}
smp_mb(); (3)
RCU_TRACE_ME(rcupreempt_trace_try_flip_a2);
return 1; (4)
}
| 1 | 遍历所有的在线 CPU。 |
| 2 | 检查 CPU 是否已经确认了计数器翻转。 |
| 3 | 确保我们不会在最后一个 CPU 确认之前检查零。这个看起来很奇怪,但是 CPU 设计者有时候会最做一些看起来奇怪的事情。 |
| 4 | 要求推进状态机。 |
rcu_try_flip_waitzero() 检查是否所有 CPU 的读端临界区都已经完成了,然后告诉状态机是否需要推进:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static int rcu_try_flip_waitzero(void)
{
int cpu;
int lastidx = !(rcu_ctrlblk.completed & 0x1);
int sum = 0;
RCU_TRACE_ME(rcupreempt_trace_try_flip_z1);
for_each_possible_cpu(cpu)
sum += per_cpu(rcu_flipctr, cpu)[lastidx];
if (sum != 0) { (1)
RCU_TRACE_ME(rcupreempt_trace_try_flip_ze1);
return 0;
}
smp_mb();
for_each_cpu_mask(cpu, rcu_cpu_online_map) (2)
per_cpu(rcu_mb_flag, cpu) = rcu_mb_needed;
RCU_TRACE_ME(rcupreempt_trace_try_flip_z2);
return 1; (3)
}
| 1 | 检查计数器之和是否为零。 |
| 2 | 设置所有 CPU 的 rcu_mb_flag 变量。 |
| 3 | 要求推进状态机。 |
rcu_try_flip_waitmb() 检查是否所有的 CPU 都执行了请求的内存屏障,并决定是否推进状态机:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
static int rcu_try_flip_waitmb(void)
{
int cpu;
RCU_TRACE_ME(rcupreempt_trace_try_flip_m1);
for_each_cpu_mask(cpu, rcu_cpu_online_map) (1)
if (per_cpu(rcu_mb_flag, cpu) != rcu_mb_done) {
RCU_TRACE_ME(rcupreempt_trace_try_flip_me1);
return 0;
}
smp_mb();
RCU_TRACE_ME(rcupreempt_trace_try_flip_m2);
return 1;
}
| 1 | 检查是否所有的 CPU 都已经完成了内存屏障。 |
__rcu_advance_callbacks() 函数推进回调函数并确认计数器翻转:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
static void __rcu_advance_callbacks(struct rcu_data *rdp)
{
int cpu;
int i;
int wlc = 0;
if (rdp->completed != rcu_ctrlblk.completed) { (1)
if (rdp->waitlist[GP_STAGES - 1] != NULL) {
*rdp->donetail = rdp->waitlist[GP_STAGES - 1];
rdp->donetail = rdp->waittail[GP_STAGES - 1];
RCU_TRACE_RDP(rcupreempt_trace_move2done, rdp);
}
for (i = GP_STAGES - 2; i >= 0; i--) {
if (rdp->waitlist[i] != NULL) {
rdp->waitlist[i + 1] = rdp->waitlist[i];
rdp->waittail[i + 1] = rdp->waittail[i];
wlc++;
} else {
rdp->waitlist[i + 1] = NULL;
rdp->waittail[i + 1] =
&rdp->waitlist[i + 1];
}
}
if (rdp->nextlist != NULL) {
rdp->waitlist[0] = rdp->nextlist;
rdp->waittail[0] = rdp->nexttail;
wlc++;
rdp->nextlist = NULL;
rdp->nexttail = &rdp->nextlist;
RCU_TRACE_RDP(rcupreempt_trace_move2wait, rdp);
} else {
rdp->waitlist[0] = NULL;
rdp->waittail[0] = &rdp->waitlist[0];
}
rdp->waitlistcount = wlc;
rdp->completed = rcu_ctrlblk.completed;
}
cpu = raw_smp_processor_id();
if (per_cpu(rcu_flip_flag, cpu) == rcu_flipped) {
smp_mb();
per_cpu(rcu_flip_flag, cpu) = rcu_flip_seen;
smp_mb();
}
}
| 1 | 检查自上次当前 CPU 调用此函数后 rcu_ctrlblk.completed 计数器是否发生了翻转。若无,则回调函数无须推进。否则 8 0- 37 行通过 lists 推进回调函数。否则第 38 - 43 行确认计数器翻转。 |
读端原语
本节解释 rcu_read_lock() 和 rcu_read_unlock() 原语,并讨论为何这两个原语不包含内存屏障。
rcu_read_lock() 的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
void __rcu_read_lock(void)
{
int idx;
struct task_struct *me = current;
int nesting;
nesting = ACCESS_ONCE(me->rcu_read_lock_nesting); (1)
if (nesting != 0) {
me->rcu_read_lock_nesting = nesting + 1;
} else {
unsigned long flags;
local_irq_save(flags);
idx = ACCESS_ONCE(rcu_ctrlblk.completed) & 0x1; (2)
smp_read_barrier_depends(); /* @@@@ might be unneeded */
ACCESS_ONCE(__get_cpu_var(rcu_flipctr)[idx])++;
ACCESS_ONCE(me->rcu_read_lock_nesting) = nesting + 1;
ACCESS_ONCE(me->rcu_flipctr_idx) = idx; (3)
local_irq_restore(flags);
}
}
| 1 | 获取该任务读端临界区的嵌套计数器。若第 8 行发现非零,则实际上已经被 rcu_read_lock() 保护了,此时在第 9 行只是简单的递增。 但是如果是最外层 rcu_read_lock(),则需要做更多工作。第 13 行和第 19 行分别用于抑制和恢复 irq。确保既不会被抢占,也不会被调度时钟中断(运行宽限期状态机)。 |
| 2 | 获取宽限期计数器。 |
| 3 | 记录旧/新计数器索引。 |
ACCESS_ONCE() 宏可以强制编译器按顺序访问,但是并不会阻止 CPU 进行指令重排。但是它确实能够确保运行在这个 CPU 上的 NMI 和 SMI 处理程序能够按顺序看到这些代码: * 若 idx 的赋值缺少 ACCESS_ONCE(),编译器将有权: 消除变量 idx 将第 16 行的代码编译成 fetch-increment-store 序列、使用 fetch 和 store 指令分离访问 rcu_ctrlblk.completed。如果 rcu_ctrlblk.completed 的值同时发生更改,则会损坏 rcu_flipctr 值。 * 若赋值语句 rcu_read_lock_nesting 被重新排序到 rcu_flipctr(第 16 行),若这两个事件之间发生 NMI,则 NMI 处理程序中的 rcu_read_lock() 会错误地认为它已经收到 rcu_read_lock() 保护。 * 若赋值给 rcu_read_lock_nesting(第 17 行)被重排到 18 行之后,并且这两个语句之间发生 NMI,则该 NMI 处理程序中的 rcu_read_lock() 将破坏 rcu_flipctr_idx,可能导致匹配的 rcu_read_unlock() 递减错误的计数器。这反过来可能导致宽限期提前结束、无限延长、或二者兼之。